Atcoder・Codeforcesの問題文から問題のカテゴリを予測するモデルを作る(スクレイピング編)
1.はじめに
競プロでは問題文や制約を見ただけで、解法がある程度予想がついてしまう、といったことが知られています。今回は問題文や制約とその問題の解法には相関関係があるという仮説のもとで、機械学習モデルを用いて、問題文と制約から解法を予測してみたいと思います。このままだとまだ曖昧なのでもう少し問題設定を具体化、単純化します。解法を予測するとは例えばDPの問題の問題文を入力するとに対してDPというラベルを、グラフの問題で深さ優先探索を用いる問題にはdfsとラベルをつけるという課題を解くモデルを作ることにします(具体的にどのようなDPやdfsをするかまでは深入りしない)。これは典型的な多クラス分類(解法が複数の組み合わせの場合や別解の存在も考慮するととマルチラベル分類)であるので、ラベル付きデータが用意できればモデルを学習させることはできそうです。この記事ではスクレイピングとデータセットの前処理について書いています。(スクレイピング初心者なので不器用な方法を取っている可能性がありますがご了承ください)
2.方法
問題文とラベルつきデータセットをatcoder、codefocesそれぞれで作成します。
Coderforcesの各問題のページの右側にはProblem tagsという欄がありタグ付けがなされており、問題のジャンルとついでにdifficultyがある程度わかるようになっています。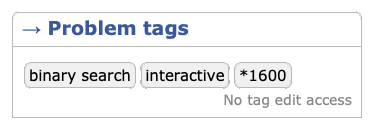
一方Atcoderでは公式でタグの機能はありません。そこで AtCoder Tags というAtcoderの問題のカテゴリを分類する外部サイトを活用します。このサイトでは有志の投票によってatcoderの問題にタグ付けされています。(さらに細分化されたタグもありますが過学習しそうなので今回は使いません)
上記サイトから問題文とタグをスクレイピングしていきます。スクレイピングはpythonとBeautifulSoupで行います。必要なライブラリをimportしておきます。
import requests from bs4 import BeautifulSoup import pandas as pd
3.1.Codeforcesの問題ページからのスクレイピング
Codeforcesの問題ページのhtmlと睨めっこしながら丁寧にコードを書いていきます。入力に関する文章はdivタグでinput-specification、出力に関する文章にはinput-specificationとclassが割り当てられているようです。問題文にはclassが割り当てられてなく、pタグから抽出しようとするとなぜか複数回抽出されてしまうので適当にアドホックな処理を入れています。tagははspanタグでtag-boxとclassが割り当てられていました。
def extract_text_from_cf_problem_page(problem_url): problem_html = requests.get(problem_url) problem_parse = BeautifulSoup(problem_html.content, "html.parser") problem_div = problem_parse.find_all("div") # 問題文の抽出,コドフォのページのhtmlをよく見て該当部分の属性で抽出 res = {"problem_text": [], "input_text": [], "output_text": [], "tags": []} for elem in problem_div: try: elem_cls = elem.get("class")[0] if elem_cls == "input-specification": res["input_text"].extend( [ paragraph.string for paragraph in elem.find_all("p") if paragraph.string is not None ] ) if elem_cls == "output-specification": res["output_text"].extend( [ paragraph.string for paragraph in elem.find_all("p") if paragraph.string is not None ] ) break except: if not res["problem_text"]: res["problem_text"].extend( [ paragraph.string for paragraph in elem.find_all("p") if paragraph.string is not None ] ) res["problem_text"] = "".join(res["problem_text"]) res["input_text"] = "".join(res["input_text"]) res["output_text"] = "".join(res["output_text"]) # タグの抽出,コドフォのhtmlをよく見て該当部分の属性で抽出 problem_span = problem_parse.find_all("span") for elem in problem_span: try: elem_cls = elem.get("class")[0] if elem_cls == "tag-box": res["tags"].append(elem.string) except: pass res["tags"] = "".join(res["tags"]) return res
3.2.URLを探索してデータセットを作成
Codeforcesの単一の問題ページから問題文と制約とタグを抽出する関数が書けたので、あとはCodeforcesの全ての問題ページからスクレイピングをしデータセットを作成していきます。 本来ならCodeforcesのページからリンクを再帰的に辿って問題文を抽出するべきでしょうが、Codeforcesの問題ページは "https://codeforces.com/problemset/problem/"の先に数字(おそらくコンテストのID)+/+アルファベット(おそらくA問題、B問題...の意味)の形で管理されているようなので、愚直に全探索してURLを取得します。最新のコンテストでの数字は1500前後で、各コンテストの問題数は大体9問以下なのでこの組み合わせで探索します。ただし中にはA1やA2といった制約だけが異なる問題(いわゆるeasy version ,hard version)があります。よってアルファベットだけではなくA1なども漏らさないように探索します(ただしA2などは問題文がほぼ同じであることや処理の時間を考えて探索しません)。URL取得にかなり時間がかかるようで、全部で14時間ほどかかりました。 最後にcsv形式で保存します。
base_url = "https://codeforces.com/problemset/problem/" prob_nums = [str(i) for i in range(200, 1500)] # 200回から最新まで抽出 capital = [chr(i) for i in range(65, 65 + 9)] # ABCDEFGHI prob_names = capital + [e + "1" for e in capital] df = { "prob_id": [], "problem_texts": [], "input_texts": [], "output_texts": [], "tag_set": [], } for num in prob_nums: for name in prob_names: prob_id = num + "/" + name df["prob_id"].append(prob_id) try: datum = extract_text_from_cf_problem_page(base_url + prob_id) df["problem_texts"].append(datum["problem_text"]) df["input_texts"].append(datum["input_text"]) df["output_texts"].append(datum["output_text"]) df["tag_set"].append(datum["tags"]) except: pass pd.DataFrame(df).to_csv("../data/cf_problem_tag_dataset.csv", index=False)
4.1.Atcoderの問題ページからのスクレイピング
同様にAtcoderの問題ページのhtmlと睨めっこします。Codeforcesの問題ページとはまた色々と仕様が違います。今回は英語の問題文を取り出したいのでlang-enと割り当てられたタグを探します。Atcoderでは問題文、制約、入力、出力と四つにsectionタグでが分けられているようですのでsectionタグで検索して最初の4つだけをそれぞれ取り出します。(この辺かなりアドホックにやっています) コードとしては次のようになります。
def extract_text_from_atcoder_problem_page(problem_url): res = {"problem_text": "", "constraint": "", "input_text": "", "output_text": ""} problem_html = requests.get(problem_url) problem_parse = BeautifulSoup( problem_html.content, "html.parser", from_encoding="utf-8" ) problem_span = problem_parse.find_all("span") for elem in problem_span: try: elem_cls = elem.get("class")[0] if elem_cls == "lang-en": ( res["problem_text"], res["constraint"], res["input_text"], res["output_text"], ) = [paragraph.text for paragraph in elem.find_all("section")][:4] except: pass return res
4.2.Atcoder TagsからURLを探索してデータセットを作成
Atcoder Tagsからはそのタグが付いている問題へのハイパーリンクがあるのでハイパーリンクをスクレイピングしてデータセットを作っていきます。タグ一覧のページから再帰的にリンクを辿ればもっとカッコよく書けそうですが、今回はとりあえず手作業で全てのタグのURLを控えておき、スクレイピングを行いました。
base_url = "https://atcoder-tags.herokuapp.com/tag_search/" tags_list = [ "Easy", "Ad-Hoc", "Searching", "Greedy-Methods", "String", "Mathematics", "Technique", "Construct", "Graph", "Dynamic-Programming", "Data-Structure", "Game", "Flow-Algorithms", "Geometry", ]
それぞれのタグが付いているatcoderの問題のurlを全て取得し、先ほどの関数を噛ませて、データセットを作成します。こちらは比較的早く終わりました(30分ほど)。
for tag in tags_list: atcoder_tags_url = base_url + tag atcoder_tags_html = requests.get(atcoder_tags_url) atcoder_tags_parse = BeautifulSoup( atcoder_tags_html.content, "html.parser", from_encoding="utf-8" ) prob_urls = [ url.get("href") for url in atcoder_tags_parse.find_all("a") if url.get("href").startswith("http") ] df = { "urls": [], "problem_texts": [], "constraints": [], "input_texts": [], "output_texts": [], "tag": [], } for url in prob_urls: try: datum = extract_text_from_atcoder_problem_page(url) df["urls"].append(url) df["problem_texts"].append(datum["problem_text"]) df["constraints"].append(datum["constraint"]) df["input_texts"].append(datum["input_text"]) df["output_texts"].append(datum["output_text"]) df["tag"].append(tag) except: pass pd.DataFrame(df).to_csv("../data/atcoder_problem_tag_dataset.csv", index=False)
4.おわり
データを取った結果、codefocesの方がデータが豊富そうでした。atcoderはそもそも日本語の問題文しかない場合もありデータが結構欠損しているイメージでした。 次は実際に機械学習モデルに作成したデータセットを学習させてみます。