np.sumよりnp.dotするほうが速い
TL;DR
- np.dotはBLASを呼び出すので、np.sumするよりnp.dotを使うほうが速い(float型に限る)
- 条件付きでsumを取る場合は中間結果を保持する必要がないため更に速くなる
- (理由)np.sumはnumpyネイティブな処理なのに比べて、np.dotはBLASを呼び出しているためより最適化された処理が行われているから?
BLASの活用
御存じの通りNumPyはPythonにおいて数値計算を効率的に行うための拡張モジュールで、NumPyで書けば大抵の計算はPythonの遅さを気にすることなく実行できます。 しかしNumPyでも呼び出す関数や書き方によって処理速度が異なってくることがあります。
実はNumPy自体もその内部で更にOpenBLASやMKLといった高速な線形代数ライブラリ(BLAS:Basic Linear Algebra Subprograms)を呼び出しています。OpenBLASやMKL内部での処理は並列化やメモリアクセスの最適化がなされているため、できるだけBLASを呼び出すような処理を書くと同じNumPyを使う場合でもより速く処理ができることが期待できます。
今回は例としてnp.sum処理をより線形代数っぽい操作に置き換えることでより高速化してみます。
np.sumをnp.dotに置き換える
適当な2次元配列Aに対して2次元目の軸について和を取る操作
A.sum(axis=1)
を考えます。この操作は線形代数的な演算で書き直すことができます。Aを$M×N$行列と見なし、すべての要素が$1$である$N$次元ベクトル$b$を用意すると
行列積$Ab$は$M$次元ベクトルとなり各要素は行列積の定義よりAの各行の列和となるのでこれはA.sum(axis=1)と同じ結果となります。実際に以下のようなテストをしてみるとちゃんと通ることがわかります。
A = np.random.randint(0, 1000, size=(5000, 5000)) b = np.ones(5000) np.testing.assert_almost_equal(A.sum(axis=1), np.dot(A, b))
A.sumとnp.dotで計算量は変わらないですが、np.dotのほうは線形代数の演算なのでBLASが呼び出されます。
条件付きのnp.sumをnp.dotで置き換える
np.sumを使うとき、特定の要素だけを足し合わせたい場合もあります。この場合、sum関数のwhere引数を作るか、またはあらかじめフラグ配列を掛けてからnp.sumすることで実現できます。例えば、足し合わせる箇所を表すベクトルをcondとすると
A=np.random.randint(0,1000,size=(5000,5000)) cond=np.random.randint(0,2,5000).astype(np.bool_) (A*cond).sum(axis=1) A.sum(axis=1,where=cond)
この場合も線形代数的な演算で書き直すことができます。先ほどのすべての要素が$1$である$N$次元ベクトル$b$の代わりに条件を満たす箇所だけ1でそうでない箇所を0にした配列condを用いて、行列積$A\cdot \rm{cond}$を考えることでBLASを呼び出しての処理を行うことが可能です。更にこの場合、行列積で求めるやり方だと(A*cond).sum(axis=1)に比べて中間変数を保持する必要がないため、その点でも効率化されます。
速度計測
以下の環境で実際に各処理の実行時間を測定してみました。
条件なしのsum処理
| 実行コード | 実行時間(np.int32) | 実行時間(np.float32) | 高速化倍率(np.int32) | 高速化倍率(np.float32) |
|---|---|---|---|---|
| A.sum(axis=1) | 5.62 ms | 7.54 ms | 1.0x | 1.0x |
| np.dot(A,b) | 8.53 ms | 2.66 ms | 0.65x | 2.83x |
int32型での計算速度はnp,sumのほうが速い結果となっていますが、float32型ではnp.dotのほうが2.83倍も高速になっています。実際にCPU使用率を見てもnp.dot計算中のほうが全てのコアが満遍なく使用されていてマシンリソースを最大限活用できているようでした。int32型の計算が遅いのはBLASが本来数値計算用に用いられるため、float型での最適化しか想定してないからでしょうか?(詳しくはわかりませんでした。)
条件付きのsum処理
| 処理内容 | 実行時間(np.int32) | 実行時間(np.float32) | 高速化倍率(np.int32) | 高速化倍率(np.float32) |
|---|---|---|---|---|
| (A*cond).sum(axis=1) | 28.0 ms | 28.8 ms | 1.0x | 1.0x |
| np.dot(A,cond) | 8.39 ms | 2.32 ms | 3.34x | 12.4x |
中間変数の保持が省かれる分、単純なsumに比べてより高速化できています。今回に限らず中間変数の保持をなるべく省くことがNumPyの高速化のカギですね。*1
まとめ
NumPyは速いが、その中でもBLASを呼び出す関数を上手く使うとより高速化できる。ただし、float型を使わないとそこまで恩恵は得らない(かえって遅くなる) 行ないたい処理が線形代数的な演算で書けるかを常に気をつける。
NumPyを用いた配列に対するelementwiseなbitcountの実装
TL;DR
- PythonとNumPyだけで配列に対してelementwiseにbitcount処理を高速に行いたいよ
- 前計算したり、bit演算だけを使うアルゴリズムを使うとNumPyと相性よくそれなりに高速で動作したよ
- CuPy使うともっと速くなるよ、カーネル融合すると更に速くなるよ
- そもそも、次のNumPyのリリースで組み込みでbitcount処理がサポートされるみたいだから、それを使うのが一番楽で速いよ
1. 概要
プログラムのパフォーマンスを改善したいとき、bool型の配列を64要素ごとにまとめて整数型とみなしてまとめて処理することで高速化をしたい場合があると思います(いわゆるbitset高速化)。 bitsetを扱う場合、各種のbit演算(AND,OR,NOT,XOR,bitshift,bitcount)を行える必要があります。そして実際の場面では配列に格納された各要素に対してこのような操作を行うことが必要になります。
Pythonでこれを実現するにはどうすればよいでしょうか? Pythonでのint型に対してのbitcount処理自体はPython3.10にて組み込みでサポートされています。
しかしご存知の通りPythonでforループを使用すると遅いですので、配列に対してelementwiseに操作を行いたい場合はNumPyを使用することになります。
幸いNumPyでもbitwise演算はほとんど用意されています。
Binary operations — NumPy v1.26 Manual
しかし1が立っているbit数をカウントするbitcount処理だけはNumpy=1.26の時点ではまだ実装されていません。bitcount処理は結構使いどころがあり、例えば(AND,OR,NOT,XOR)などの演算を行った最後に 1が立っているbitの個数を集計したいときなどに使用します。
bitcount処理をnumpyで行いたい場合は自分で関数を書く必要があります。 この記事では、bitcount処理をNumPy配列に対してelementwiseに行う場合、どのように実装するのが一番速いのか検証します。
2. 比較した方法
この記事では以下の方法でそれぞれ性能評価しました。
- bool型配列に対する単純なsumで計算する方法(ベンチマーク)
- python組み込みのbitcount関数を使用する方法
- 前計算しておいたテーブルを活用する方法
- bitwise演算の組み合わせによる効率的なアルゴリズムを使用する方法
- (おまけ)Cupyを使用した高速化
- (おまけ)近日Numpyに追加される予定のbitcountのuniversal functionを使用する方法
3. 実験設定
長さ$n=200,000$のランダムな符号なし64bit整数の配列に対して、すべての要素のbitcountをした結果を返す処理の速度を比較します。
def elementwise_bitcount(arr:np.ndarray) -> np.ndarray: # 何らかのbitcountアルゴリズム return res #以下の処理時間を計測 arr = np.random.randint(low=0, hight=2**63-1, size=n, dtype=np.uint64) res = elementwise_bitcount(arr)
実験環境は以下の通りです。
- Python=3.11
- Numpy=1.26
- CPU: 12th Gen Intel(R) Core(TM) i9-129000K
- GPU: NVIDIA GeForce RTX 3080
4. 実験結果
まずは1~4までの方法で実際に処理時間の計測結果と分析を行います。5と6の方法については後述します。
1.bool型配列に対する単純なsumで計算する方法(ベンチマーク)
まずはベンチマークとして、各要素を64bit整数ではなく長さ64のbool型配列で表現した、$n×64$のbool型配列に対して、単純に足し算を行うことでbitcountを実現する方法を試してみます。単純に考えるとこれは各要素に対して64回の演算を行っているので効率は悪そうです。
def naive_bitcount(arr : np.ndarray) -> np.ndarray: res = np.sum(arr, axis=1) return res
処理時間の計測結果は1回あたり平均7455 μsでした。
2.Python組み込みのbitcount関数を使用する方法
Python組込みのbitcount関数をnumpyのvectorize関数でベクトル化して適用してみます。NumPyのvectorize関数は本質的にはpythonのforループを回しているだけなのでそこまで速いわけではないですが、組込みのbitcount関数が十分速いので期待できそうです。
f = np.vectorize(lambda x: x.bit_count()) def pybuiltin_bitcount(arr: np.ndarray): return f(arr)
処理時間の計測結果は1回あたり平均14877 μsでした。
むしろベンチマークの方法に比べて2倍遅くなってしまいました。単純にvectorizeするだけでは速くはならないようです。
3.前計算しておいたテーブルを活用する方法
次は予め全ての整数に対してbitcountの結果を前計算しておいて、その結果を毎回参照する方法です。とはいえ64bitで表現できる整数すべてについて前計算すると膨大なメモリが必要になります。
そこで16bit整数で表現できる0~65535までbitcountの結果を前計算しておき、64bit整数を16bitずつに分けてそれぞれのbitcountを足すという方法を取ります。(16bitで区切るのは単純にキリが良いからで、メモリが潤沢に使用できる場合だともっとたくさんの桁まで前計算してもよいかもしれません。)
またNumPyのfancy indexing機能で上手く書くことで、前計算した結果を配列の各要素に適用することができます。
# 16bitで表現できるすべての整数のbitcountの結果を前計算しておく precalc_16bit = np.array( [n.bit_count() for n in range(2**16 - 1)], dtype=np.uint8 ) def precalc_bitcount(arr: np.ndarray): # fancy indexingでarrの各要素を前計算した結果に置き換えた配列にする arr = precalc_16bit[arr] return arr.sum(axis = 1)
処理時間の計測結果は1回あたり平均3426 μsでした。
ベンチマークの方法に比べて2倍くらい速くなっています。16bitごとに分割した分、最後にsumを取る分の計算回数は増えますが、前計算によりbitcount計算が省略できたのと、NumPyで完結するよう処理できた部分が高速化に貢献していますね。
4.bitwise演算の組み合わせによる効率的なアルゴリズムを使用する方法
実はbitcount処理をbitwise演算の組み合わせだけで実現する効率的なアルゴリズムが知られています。詳細なアルゴリズムの説明は
などを参照ください。以下のコードは実際に合計17回のbit演算でuint64型の整数をbitcountした結果を返すことができます。
def efficient_bitcount(n: np.uint64) -> np.uint64: n -= (n >> 1) & 0x5555555555555555 n = (n & 0x3333333333333333) + ((n >> 2) & 0x3333333333333333) n = (n + (n >> 4)) & 0x0F0F0F0F0F0F0F0F n += n >> 8 n += n >> 16 n += n >> 32 return n & 0x7F
上記の関数はif文や参照を使用していないbit演算だけで構成されているので、引数のnをそのままNumPyの配列に変えてあげれば自動的に各要素で同じ計算を行ってくれるため、NumPyで完結する処理だけでelementwiseにbitcount処理を行うことができます。
結果は1回あたり平均3292 μsでした。
ベンチマークの方法に比べて2倍くらい速くなっており、また前計算で求める方法よりも少し速くなっています。bool型配列の場合と比べて配列サイズが1/64になっているとはいえ、bitcointのために17回の演算を行っているため思ったより高速化できていない印象です。
これは単純に計算回数の問題だけではなくNumPyの性質も関係してきます。この方法では17回の計算の度にNumPyの関数の呼び出し、それぞれの計算の中間結果の保存のためのメモリ確保といった色々なオーバーヘッドが発生しています。*1
5. まとめ.Part1
| 方法 | 処理時間(μs) | 高速化倍率 |
|---|---|---|
| 1. ベンチマーク | 7455 | 1.0x |
| 2. python組み込みのbitcount関数を使用する方法 | 14877 | 0.5x |
| 3. 前計算しておいたテーブルを活用する方法 | 3426 | 2.17x |
| 4. bitwise演算の組み合わせによる効率的なアルゴリズムを使用する方法 | 3292 | 2.26x |
というわけで現在のPython3.11,NumPy1.26の時点では4番の方法で計算するのが最も速いという結果になりました。メモリが潤沢に使える場合は3の方法で前計算する整数の範囲を更に広げることでより高速化できるかもしれません。ともあれ、ベンチマークの方法よりは大体2倍程度は速くなるので試してみる価値はあると思います。
6.おまけ
上記の2倍程度の高速化では満足できない人のために更に頑張ってみましょう。
CuPyを使用した高速化.Part1
先ほど、4番の方法はNumPyで完結する処理だけで書けることを述べました。そこでNumPyの処理をCuPyで書き換えることでGPUを活用することができます。特に今回のような単純なelementwiseな演算については並列化の恩恵をかなり受けることが可能なので、高速化が期待できます。CuPyはインストールが若干面倒ですが、インストールができてしまえば今回の場合ほとんど既存のコードに手を加えることなくCuPy化が可能です。
import cupy as cp def efficient_bitcount(arr: cp.uint64) -> cp.uint64: arr -= (arr >> 1) & 0x5555555555555555 arr = (arr & 0x3333333333333333) + ((arr >> 2) & 0x3333333333333333) arr = (arr + (arr >> 4)) & 0x0F0F0F0F0F0F0F0F arr += arr >> 8 arr += arr >> 16 arr += arr >> 32 return arr & 0x7F
処理時間の計測結果は1回あたり平均194 μsでした。*2
そもそも配列のサイズが大きめのでGPUのほうが有利なのは当然ですが、CPUの場合と比較して16倍の高速化を達成しています。
CuPyを使用した高速化.Part2
CuPyを使用することで劇的に高速化できることはわかりましたが、先ほど述べたようにCuPyもNumPyと同様に計算の度に関数の呼び出し、それぞれの計算の中間結果の保存のためのメモリ確保といった色々なオーバーヘッドが発生します。CuPyにはカーネル融合という機能が用意されており、これを使うことで更に高速化することができます。詳細は以下を参照
CuPy カーネル融合の拡張 - Preferred Networks Research & Development
User-Defined Kernels — CuPy 12.2.0 documentation
今回の場合は以下のように自作のbitcount用のカーネルを作成し呼び出します。
cp_kernel_fusion_bitcount = cp.ElementwiseKernel(
"uint64 x",
"uint64 z",
"""
z -= (x >> 1) & 0x5555555555555555;
z = (z & 0x3333333333333333) + ((z >> 2) & 0x3333333333333333);
z = (z + (z >> 4)) & 0x0F0F0F0F0F0F0F0F;
z += z >> 8;
z += z >> 16;
z += z >> 32;
""",
"bitcount_kernel",
)
cp_kernel_fusion_bitcount(x)
処理時間の計測結果は1回あたり平均22 μsでした。
カーネル融合をしないCuPyの方法より10倍以上速くなりました。今回のようにCuPyでの演算を何回も行う場合はカーネル融合の恩恵が大きいようです。
近日Numpyに追加される予定のbitcountのuniversal functionを使用する方法
CuPyとカーネル融合を使って高速化できることはわかりましたが、CPUとNumPyだけではこれ以上高速化は無理そうでしょうか。 繰り返しになりますが、現状の方法のボトルネックはbitcount時のNumPy配列に対する17回の演算です。これがCuPyのカーネル融合のようにNumPy内部で計算されるようになれば、高速化できそうです。
実は現在開発中のNumPyではbicount処理がNumPy組込みのuniversal functionとして実装される予定です! numpy.org
開発中のNumPyの機能をお手軽に試すには、
GitHub - numpy/numpy: The fundamental package for scientific computing with Python.
で用意されているGihub Codespacesの環境でNumPyをソースからビルドすることで使用することができます。*3
Codespacesに入ったらnumpyのリポジトリに入り
pip install .
でmainブランチにあるNumPyをビルドします。ビルドができたらnumpyというフォルダができていると思うのでその中でPythonを起動することでmainブランチにあるNumPyの関数が使えるようになります。
実際にCodespaces内で以下のコードを実行して、4の方法と比較してみます。
import numpy as np #開発中のNumpyをimport np.bitwise_count(arr)
処理時間の計測結果は同じくCodespaces内で実行したbitwise演算の組み合わせによる効率的なアルゴリズムを使用する方法と比べて、10倍ほど速くなりました。(実験環境がローカルと異なるので倍率で比較しています。)
よって新たなNumPyがリリースされれば、bitwise_countを使うのが一番楽に高速化できるということになります。
まとめ.Part2
今回試した方法をすべてまとめました。GPUが使えて配列のサイズが大きい場合にはCuPyのカーネル融合による方法が一番速いです。 NumPyだけの場合、次のリリースで追加されるbitwise_countを使うのが速いですが、リリースされるまでは3や4の方法を使うのが良さそうです。*4
| 方法 | 処理時間(μs) | 高速化倍率 |
|---|---|---|
| 1. ベンチマーク | 7455 | 1.0x |
| 2. python組み込みのbitcount関数を使用する方法 | 14877 | 0.5x |
| 3. 前計算しておいたテーブルを活用する方法 | 3426 | 2.17x |
| 4. bitwise演算の組み合わせによる効率的なアルゴリズムを使用する方法 | 3292 | 2.26x |
| 5.1 CuPy | 194 | 38.4x |
| 5.2 CuPy(カーネル融合) | 22 | 338x |
| 6. numpy.bitwise_count | 329(推定) | 22.6x |
Atcoder・Codeforcesの問題文から問題のカテゴリを予測するモデルを作る(スクレイピング編)
1.はじめに
競プロでは問題文や制約を見ただけで、解法がある程度予想がついてしまう、といったことが知られています。今回は問題文や制約とその問題の解法には相関関係があるという仮説のもとで、機械学習モデルを用いて、問題文と制約から解法を予測してみたいと思います。このままだとまだ曖昧なのでもう少し問題設定を具体化、単純化します。解法を予測するとは例えばDPの問題の問題文を入力するとに対してDPというラベルを、グラフの問題で深さ優先探索を用いる問題にはdfsとラベルをつけるという課題を解くモデルを作ることにします(具体的にどのようなDPやdfsをするかまでは深入りしない)。これは典型的な多クラス分類(解法が複数の組み合わせの場合や別解の存在も考慮するととマルチラベル分類)であるので、ラベル付きデータが用意できればモデルを学習させることはできそうです。この記事ではスクレイピングとデータセットの前処理について書いています。(スクレイピング初心者なので不器用な方法を取っている可能性がありますがご了承ください)
2.方法
問題文とラベルつきデータセットをatcoder、codefocesそれぞれで作成します。
Coderforcesの各問題のページの右側にはProblem tagsという欄がありタグ付けがなされており、問題のジャンルとついでにdifficultyがある程度わかるようになっています。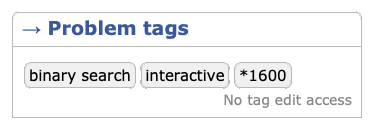
一方Atcoderでは公式でタグの機能はありません。そこで AtCoder Tags というAtcoderの問題のカテゴリを分類する外部サイトを活用します。このサイトでは有志の投票によってatcoderの問題にタグ付けされています。(さらに細分化されたタグもありますが過学習しそうなので今回は使いません)
上記サイトから問題文とタグをスクレイピングしていきます。スクレイピングはpythonとBeautifulSoupで行います。必要なライブラリをimportしておきます。
import requests from bs4 import BeautifulSoup import pandas as pd
3.1.Codeforcesの問題ページからのスクレイピング
Codeforcesの問題ページのhtmlと睨めっこしながら丁寧にコードを書いていきます。入力に関する文章はdivタグでinput-specification、出力に関する文章にはinput-specificationとclassが割り当てられているようです。問題文にはclassが割り当てられてなく、pタグから抽出しようとするとなぜか複数回抽出されてしまうので適当にアドホックな処理を入れています。tagははspanタグでtag-boxとclassが割り当てられていました。
def extract_text_from_cf_problem_page(problem_url): problem_html = requests.get(problem_url) problem_parse = BeautifulSoup(problem_html.content, "html.parser") problem_div = problem_parse.find_all("div") # 問題文の抽出,コドフォのページのhtmlをよく見て該当部分の属性で抽出 res = {"problem_text": [], "input_text": [], "output_text": [], "tags": []} for elem in problem_div: try: elem_cls = elem.get("class")[0] if elem_cls == "input-specification": res["input_text"].extend( [ paragraph.string for paragraph in elem.find_all("p") if paragraph.string is not None ] ) if elem_cls == "output-specification": res["output_text"].extend( [ paragraph.string for paragraph in elem.find_all("p") if paragraph.string is not None ] ) break except: if not res["problem_text"]: res["problem_text"].extend( [ paragraph.string for paragraph in elem.find_all("p") if paragraph.string is not None ] ) res["problem_text"] = "".join(res["problem_text"]) res["input_text"] = "".join(res["input_text"]) res["output_text"] = "".join(res["output_text"]) # タグの抽出,コドフォのhtmlをよく見て該当部分の属性で抽出 problem_span = problem_parse.find_all("span") for elem in problem_span: try: elem_cls = elem.get("class")[0] if elem_cls == "tag-box": res["tags"].append(elem.string) except: pass res["tags"] = "".join(res["tags"]) return res
3.2.URLを探索してデータセットを作成
Codeforcesの単一の問題ページから問題文と制約とタグを抽出する関数が書けたので、あとはCodeforcesの全ての問題ページからスクレイピングをしデータセットを作成していきます。 本来ならCodeforcesのページからリンクを再帰的に辿って問題文を抽出するべきでしょうが、Codeforcesの問題ページは "https://codeforces.com/problemset/problem/"の先に数字(おそらくコンテストのID)+/+アルファベット(おそらくA問題、B問題...の意味)の形で管理されているようなので、愚直に全探索してURLを取得します。最新のコンテストでの数字は1500前後で、各コンテストの問題数は大体9問以下なのでこの組み合わせで探索します。ただし中にはA1やA2といった制約だけが異なる問題(いわゆるeasy version ,hard version)があります。よってアルファベットだけではなくA1なども漏らさないように探索します(ただしA2などは問題文がほぼ同じであることや処理の時間を考えて探索しません)。URL取得にかなり時間がかかるようで、全部で14時間ほどかかりました。 最後にcsv形式で保存します。
base_url = "https://codeforces.com/problemset/problem/" prob_nums = [str(i) for i in range(200, 1500)] # 200回から最新まで抽出 capital = [chr(i) for i in range(65, 65 + 9)] # ABCDEFGHI prob_names = capital + [e + "1" for e in capital] df = { "prob_id": [], "problem_texts": [], "input_texts": [], "output_texts": [], "tag_set": [], } for num in prob_nums: for name in prob_names: prob_id = num + "/" + name df["prob_id"].append(prob_id) try: datum = extract_text_from_cf_problem_page(base_url + prob_id) df["problem_texts"].append(datum["problem_text"]) df["input_texts"].append(datum["input_text"]) df["output_texts"].append(datum["output_text"]) df["tag_set"].append(datum["tags"]) except: pass pd.DataFrame(df).to_csv("../data/cf_problem_tag_dataset.csv", index=False)
4.1.Atcoderの問題ページからのスクレイピング
同様にAtcoderの問題ページのhtmlと睨めっこします。Codeforcesの問題ページとはまた色々と仕様が違います。今回は英語の問題文を取り出したいのでlang-enと割り当てられたタグを探します。Atcoderでは問題文、制約、入力、出力と四つにsectionタグでが分けられているようですのでsectionタグで検索して最初の4つだけをそれぞれ取り出します。(この辺かなりアドホックにやっています) コードとしては次のようになります。
def extract_text_from_atcoder_problem_page(problem_url): res = {"problem_text": "", "constraint": "", "input_text": "", "output_text": ""} problem_html = requests.get(problem_url) problem_parse = BeautifulSoup( problem_html.content, "html.parser", from_encoding="utf-8" ) problem_span = problem_parse.find_all("span") for elem in problem_span: try: elem_cls = elem.get("class")[0] if elem_cls == "lang-en": ( res["problem_text"], res["constraint"], res["input_text"], res["output_text"], ) = [paragraph.text for paragraph in elem.find_all("section")][:4] except: pass return res
4.2.Atcoder TagsからURLを探索してデータセットを作成
Atcoder Tagsからはそのタグが付いている問題へのハイパーリンクがあるのでハイパーリンクをスクレイピングしてデータセットを作っていきます。タグ一覧のページから再帰的にリンクを辿ればもっとカッコよく書けそうですが、今回はとりあえず手作業で全てのタグのURLを控えておき、スクレイピングを行いました。
base_url = "https://atcoder-tags.herokuapp.com/tag_search/" tags_list = [ "Easy", "Ad-Hoc", "Searching", "Greedy-Methods", "String", "Mathematics", "Technique", "Construct", "Graph", "Dynamic-Programming", "Data-Structure", "Game", "Flow-Algorithms", "Geometry", ]
それぞれのタグが付いているatcoderの問題のurlを全て取得し、先ほどの関数を噛ませて、データセットを作成します。こちらは比較的早く終わりました(30分ほど)。
for tag in tags_list: atcoder_tags_url = base_url + tag atcoder_tags_html = requests.get(atcoder_tags_url) atcoder_tags_parse = BeautifulSoup( atcoder_tags_html.content, "html.parser", from_encoding="utf-8" ) prob_urls = [ url.get("href") for url in atcoder_tags_parse.find_all("a") if url.get("href").startswith("http") ] df = { "urls": [], "problem_texts": [], "constraints": [], "input_texts": [], "output_texts": [], "tag": [], } for url in prob_urls: try: datum = extract_text_from_atcoder_problem_page(url) df["urls"].append(url) df["problem_texts"].append(datum["problem_text"]) df["constraints"].append(datum["constraint"]) df["input_texts"].append(datum["input_text"]) df["output_texts"].append(datum["output_text"]) df["tag"].append(tag) except: pass pd.DataFrame(df).to_csv("../data/atcoder_problem_tag_dataset.csv", index=False)
4.おわり
データを取った結果、codefocesの方がデータが豊富そうでした。atcoderはそもそも日本語の問題文しかない場合もありデータが結構欠損しているイメージでした。 次は実際に機械学習モデルに作成したデータセットを学習させてみます。
O(1) extra space complexity を考える
競プロでは時間計算量が重視されますが空間計算量に注目して解くのも楽しいよというお話です。
Extra time complexityとは
突然ですが、次のような問題を考えてみましょう。
https://leetcode.com/problems/single-number/
問題概要
ひとつの値を除いて、同じ値がちょうど二回ずつ現れる整数列(例えば[1,1,2,2,3]のようなもの)が与えられたとき、一度しか現れない値を求めよ
解法
これは例えばunordered_mapを使って各値の出現回数をメモすれば解けます。
int solve(vector<int> &nums) { unordered_map<int, int> mp; for(auto &e : nums) { mp[e]++; } for(auto &e : nums) { if(mp[e] == 1) return e; } }
この解法の計算量は時間計算量 、空間計算量
となります。
さてここで問題の注釈を見ると追加の条件として
Could you implement a solution with a linear runtime complexity and without using extra memory?
とあります。ここで一応用語を定義しておきます。
与えられた入力の分の空間計算量を除いた空間計算量のことを extra space complexityとよぶ
この問題の追加の条件は言い換えると の extra space complexityで解けということになります。(全く他のメモリを使うなという風にも解釈できますが、どうやらそうではないようです)
上の解法では与えられた配列numsに加えてunordered_mapを使っているのでO(n)分の追加の空間計算量がかかってしまい不適です。
実は排他的論理和を使うとこの問題は extra time complexityで次のように解けます。
解法
初期値0のint型の変数aを用意してnumsの各要素との排他的論理和を取っていけば、最後のaの値がnumsで一度しか現れない値となります。なぜなら同じ数同士の排他的論理和は となるので二回現れる数は最終的には消えてしまい、一度しか現れない数だけが残るからです。
int solve(vector<int> &nums) { int a = 0; for(auto &e : nums) { a ^= e; } return a; }
この解法では変数aだけを用いているのでこの解法のextra space complexityはO(1)です。
問題
以下 extra time complexityを要求される問題を何問か紹介しようと思います。
Missing Number
https://leetcode.com/problems/missing-number/
問題概要
長さの配列に
の範囲の整数が重複なく入っています、
のうち配列に現れない数を
extra space complexityで出力してください
解法
を
から
までの和とします。配列の各要素を
から引いていくと最後の
の値が配列に現れない数となります。新たな変数として
しか用いていないので
extra space complexityで解けました。
Increasing Triplet Subsequence
https://leetcode.com/problems/increasing-triplet-subsequence/
問題概要
与えられた整数列から単調増加となるような長さの部分列が取れるかどうかを
extra space complexityで判定してください
解法
extra space complexityを気にせず解くならば真ん中の数に注目して左右に自分より小さい数と大きい数があるか判定する解法が自然でしょうか。これは前からの累積minと後ろからの累積maxを使えばできますがそれらを保存するのに
の空間計算量が必要となります。
extra space complexityで解くなら次のように貪欲に1番目と2番目の要素を決めていき、三番目の要素が条件を満たすかを判定すれば良いでしょう。
変数firstとsecondを用意する
数列を前から見ていき
- secondより大きいならtrueを返す
- firstより大きくsecondより小さいならsecondを更新
- first以下ならfirstを更新
最後まで見てもtrueを返してないならfalseを返す
上の手順では一見firstを更新したときsecondが更新されず、firstとsecondが逆になるかもしれませんが(入力例として[3,4,1,5]などで発生する)、3番目の要素の候補がsecondより大きければ、現時点でのfirst及び更新前のfirstよりも大きいので結局答えはtrueになります。
bool solve(vector<int> &nums) { int n = nums.size(); if(n < 3) { return false; } int first = nums[0], second = INT_MAX; for(int i = 1; i < n; i++) { if(nums[i] > second) { return true; } if(nums[i] <= second && nums[i] > first) { second = nums[i]; } if(nums[i] <= first) { first = nums[i]; } } return false; }
これなら追加の空間計算量は3つ変数を追加しただけなので extra space complexityを達成できました。
First Missing Positive
https://leetcode.com/problems/first-missing-positive/
問題概要
与えられた整数列に出現しない最小の自然数を extra space complexityで出力せよ
解法
整数列の長さをとします。重要な考察として整数列に出現しない最小の自然数は
の範囲に必ずあります。よって整数列のうち
までの数の出現をメモすれば
この問題は解けます。しかしこれは空間計算量
となってしまい不適です。この問題を解くには入力の整数列用の配列を再利用します。この先は1-indexで話を進めます。
また整数列を
とします。以下のような手順で
に現れる
までの数の出現を
に直接メモしていきます。
- 整数列のうち0以下の要素を全て
に置き換える(これにより全ての要素は正になる)
- 全ての
について
かつ [tex:a{abs(a_i)}]が正ならば[tex:a{abs(a_i)}]を
倍する
のうち初めて正である要素のインデックスが与えられた整数列に出現しない最小の自然数と一致するので出力する、存在しないならば
このように数列の符号を直接書き換えることによって数の出現を追加の空間計算量を使うことなくメモしていくことができ extra space complexityでこの問題が解けました。
int n = nums.size(); for(int i = 0; i < n; i++) { if(nums[i] <= 0) { nums[i] = n + 1; } } for(int i = 0; i < n; i++) { if(abs(nums[i]) <= n && nums[abs(nums[i]) - 1] > 0) { nums[abs(nums[i]) - 1] *= -1; } } for(int i = 0; i < n; i++) { if(nums[i] > 0) { return i + 1; } } return n + 1;
Find the Duplicate Number
最後の問題です。youtubeで558万回再生されたほどの超有名な問題です。
https://leetcode.com/problems/find-the-duplicate-number/
問題概要
長さの整数列が与えられます。各要素は
の範囲に収まっています。更に数列内に重複して現れる数は1種類であることが保証されます。数列内で重複して現れる数を
extra space complexity出力してください、ただし追加の制約として与えられた数列を書き換えてはいけません
解法
追加の制約よりさっきの問題のように元の数列の値をいじることでメモリを再利用することもできません。この問題は二分探索による時間計算量かつ
extra space complexityで解くことができます。
ある値
を決めたとき数列の全ての要素のうち
以下の要素の個数を
とします。これは
が重複している数より小さいときは
となります。なぜなら
が重複している数より小さいときは
までの数は高々1回しか現れないので
は最大でも
にしかなりません。同様に考えると、逆に
が重複している数以上のときは
になります。この性質からXを二分探索することで重複する数を探すことができます。
int solve(vector<int> &nums) { int l = 0, r = nums.size() + 1; int c; while(l + 1 < r) { c = 0; for(int &elem : nums) c += (elem <= (l + r) / 2); if(c <= (l + r) / 2) l = (l + r) / 2; else r = (l + r) / 2; } return r; }
変数を3個追加しているだけなので時間計算量かつ
extra space complexityで解けました。
別解
実はこの問題は時間計算量かつ
extra space complexityで解けることが知られています。数列をnumsとすると、各要素は
の範囲に収まっているので次のような遷移を考えることができます(1-indexとします)。
x, nums[x], nums[nums[x]], nums[nums[nums[x]]], ....
この遷移からループのある連結リストを構成できます。例えば数列[2,6,4,1,3,1,5]において2からスタートすると
2->4->3->1->6->5->1->6->5->1->6->5->...
という感じになり、1->6->5をループします。このループの入り口の数が重複する数となります。よってループの入り口を検出すれば良いことになりますが、これはFloyd's cycle-finding algorithmによって行うことができます。そしてFloyd's cycle-finding algorithmは実は extra space complexityのアルゴリズムとなっています。よってこの問題が時間計算量
かつ
extra space complexityで解けます。
まとめ
extra time complexityで問題を解こうとすると、時間計算量を落とすときとはまた違った発想が要求されるのでこういう問題は結構好きです。ただどう頑張っても全体としてみれば定数倍しか改善されていないのがアレですが。
最後に紹介しきれなかった問題をいくつか列挙します。
https://leetcode.com/problems/rotate-array/
https://leetcode.com/problems/find-all-duplicates-in-an-array/
英語コーパスをAzure Database for PostgreSQLに保管して、pythonからクエリを投げて例文検索するGUIを作る
動機
最近諸事情で英語の文章を書かなければいけず、いろいろ四苦八苦している。英語の文章を書くうえで、不自然でない表現を心がけなくてはいけないが、これが難しい。辞書を引くだけでは基本的に意味しか載っていないので使い方がわからない。そこで役に立つのがその単語が使われている例文を、たくさんあたってみることだ。そして、これまた諸事情により自分のPCになぜか12GBほどの英語のコーパスがあったので、このコーパスから指定した単語を含む文を抽出するプログラムを作ろうとしたのがきっかけである。
コーパス処理
自分が持っていた英語コーパスはtxtファイルに無造作に英語の文章が大量に入っているだけなのでまずはこれをセンテンス単位に分割した。
英文のセンテンス単位の分割だが、基本的にはピリオドで区切れば良いのだが、Mr.とかMs.はピリオドで終わってるがセンテンスは終わらないし、 他にも He quoted as saying "I have hoge.".などとピリオドで区切ればいいと言えない場面も多々ある。Natural Language Toolkitを使えばこの辺の細々した条件を(ある程度)よしなにやってくれる。
from nltk.tokenize import sent_tokenize #文章をセンテンス単位で分割しそのリストを返す関数
さてこれでコーパスを処理すれば良いが、残念ながら自分の16GBメモリには載りそうもないので、なんとかする。色々方法はあると思うが自分はデータを分割して読み込むことにした。データ分割はLinuxコマンドの
split -l 100000 corpus_utf.txt split_data/splt_
などで適当にやる。次のコードを叩いてsentence.txtというセンテンス単位で改行されたtxtファイルを作る。
import glob split_files=glob.glob("./split_data/*") for file in split_files: with open(file) as f: s = f.read() sent_list = sent_tokenize(s) with open('sentence.txt', 'a') as f: for sent in sent_list: f.write("%s\n" % sent)
これで前処理は完了である。ちなみにsentence.txtは1億行ぐらいありました。
Azure Database for PostgreSQLにあげる
sentence.txtに対して直接処理するのははメモリ的にも実行時間的にも厳しいと感じた。ここでちょうどクラウドサービスとSQLに慣れておきたいと思っていたので、このファイルをAzure Database for PostgreSQLにアップロードしてSQLを叩いて結果を返してもらうことを思いつく。Azureは幸い無料試用期間があるので無料でサーバーを建てさせてもらった。Pythonからデータベースにアクセスするにはpsycopg2を使った。pycopg2ではconnectオベジェクトでデータベースにつないで、cursorオブジエクトでSQLクエリを投げることができる。使い終わったらちゃんとclose()を呼び出さないといけないなど、そのままではやや使い勝手が悪いと思ったので(connectionとかcursorとかをcloseとかを気にせず)SQLクエリを文字列として入力して結果を返す関数exec_queryを自前で作っておく。
import psycopg2 def exec_query(query): with psycopg2.connect(db_info) as connection: with connection.cursor() as cur: cur.execute(query) try: res=cur.fetchall() except : return None return res
なお接続にはAzureに設定したユーザー名やサーバー名やパスワードが要求される。上のコードでdb_infoに当たるものがそうである。実際にはdb_infoにはAzure Database for PostgreSQLの接続文字列が入っている。
exec_query("create table sentences (sentence text)")
でまずテーブルを作る。今回は各レコードにセンテンスがひとつ入ったテーブルを作るので上のようなSQLクエリを投げる。ここで型をtext型にしたのはvarchar型ではvarchar型の最大文字数を超えるセンテンスがあったためである。 ではテーブルsentencesを作ってデータをインポートしよう。しかしSQLのCOPYクエリがAzureのセキュリティの関係で使えないので(ここはかなり詰まった)pycopg2のcopy_from関数を使ってimportしていく。
exec_query("truncate table sentences") with psycopg2.connect(db_info) as connection: with connection.cursor() as cur: f=open("sentence.txt") cur.copy_from(f,"sentences",sep="#") f.close()
これでサーバーにセンテンスがレコードとして保存されたテーブルが作成されたので後は指定したワードでSQLクエリを作ってサーバーに投げて結果を取得すればokである。 一連の処理を関数化しておく。
def search_sent(word): rslt=exec_query("select sentence from sentences where sentence like '% {} %'".format(word)) print(rslt)
tkinterでGUIを作る
これで例文検索はできるようになったのだが、少し寂しいのでGUIで使えるようにもうちょっといじる。目標としては
 のようにテキストボックスに入れた単語を含む例文を検索ボタンを押すことで右の大きなテキストボックスに該当単語をハイライトして例文を表示する機能を実装したい。
見栄えはどうでもいいので標準ライブラリのtkinterを使う。
のようにテキストボックスに入れた単語を含む例文を検索ボタンを押すことで右の大きなテキストボックスに該当単語をハイライトして例文を表示する機能を実装したい。
見栄えはどうでもいいので標準ライブラリのtkinterを使う。
import Tkinter as tk
まず検索ワードを入れる小さなテキストボックスは
txt = tk.Entry(width=20)
で作る。 右の大きなテキストボックスはネットで調べてみると次のようにtkinterのFrameクラスを継承し定義するとうまくいくという。
class SbTextFrame(tk.Frame): def __init__(self, master): super().__init__(master) text = tk.Text(self, wrap='none', undo=True) x_sb = tk.Scrollbar(self, orient='horizontal') y_sb = tk.Scrollbar(self, orient='vertical') x_sb.config(command=text.xview) y_sb.config(command=text.yview) text.config(xscrollcommand=x_sb.set, yscrollcommand=y_sb.set) text.grid(column=0, row=0, sticky='nsew') x_sb.grid(column=0, row=1, sticky='ew') y_sb.grid(column=1, row=0, sticky='ns') self.columnconfigure(0, weight=1) self.rowconfigure(0, weight=1) self.text = text self.x_sb = x_sb self.y_sb = y_sb
次にボタンを押した時の挙動を関数として記述する。search_sentの結果をtextframe.textにinsertメソッドで入力している。ハイライトをつける機能はtag機能を使って少しゴリ押しで書いた。
def get_word_and_search(): word = txt.get() sents = search_sent(word) textframe.text.delete("1.0", "end") textframe.text.insert("1.0", "\n\n".join(sents)) # 該当単語にハイライトを作る部分 for i, sent in enumerate(sents): ind = 2*i+1 s = sent.find(word) t = s+len(word) textframe.text.tag_add("highlight", str( ind)+"."+str(s), str(ind)+"."+str(t)) textframe.text.tag_config("highlight", foreground="red")
後は適当にタイトルをつけたりボタンなどを配置し関数を紐付ける。
# Tkクラス生成 root = tk.Tk() # 画面サイズ root.geometry('1400x600') # 画面タイトル root.title('例文検索') # 表示 # テキストボックス lbl = tk.Label(text='検索ワード') lbl.pack(padx=20, side='left') txt.pack(padx=20, side='left') # 検索ボタン設置 btn = tk.Button(root, text='検索', command=get_word_and_search) btn.pack(padx=20, side='left') # 結果出力 textframe = SbTextFrame(root) textframe.pack(side="top", expand=True) root.mainloop()
これで一応完成。いろんな単語を入れてみたが大体1秒以内には結果が返ってくるのでとりあえず満足。weblioの例文検索使えばよくない?
プール方式による効率的PCR検査
はじめに
この記事はとある朝日新聞デジタルの記事"多くの検体「まとめて」PCR検査で、件数を増やせる?"に書かれていた、PCR検査の手法が面白いなと思い、自分なりに色々実験した結果と考察を載せたものです。なお私はPCR検査自体についての専門的知識は全く持っていません。この記事はあくまで極端に理想化された状況での思考実験だと思ってください。
PCR検査とは
DNAサンプルから特定領域を数百万〜数十億倍に増幅する一連の反応またはその技術である
DNAポリメラーゼと呼ばれる酵素の働きを利用して、一連の温度変化のサイクルを経て任意の遺伝子領域やゲノム領域のコピーを指数関数的(ねずみ算的、連鎖的)に増幅することで、少量のDNAサンプルからその詳細を研究するに十分な量にまで増幅することが目的である
のような手法です。専門的な内容については門外漢なのでなんとも言えませんが、一回の検査にとても時間がかかる検査方法のようで、これを患者一人一人に行っているので多大なコストがかかっているようです。
プール方式PCR検査
前述の朝日新聞デジタルの記事によると
理論的には500検体のうち1検体にでもウイルスが含まれていれば、ウイルスの核酸は増幅され陽性に出るはずです。
とあるようにPCR検査を一人一人に行うのではなく検体をいくつかにまとめて検査することで初めに陽性の検体の当たりをつけて、効率化を図っているようです。なんとも豪快で本当にそれでいいのか?という感じですが、この記事の記述から以下のことが推測されます。 - 検体を混ぜることはPCR検査を行うことと比べて簡単に行うできる - 検体に1つでもウイルスが含まれていれば、他の検体と混ぜた後PCR検査をしても検出できる - 検体を混ぜてPCR検査しても一回の検査にかかる時間はあまり変わらない
もし陽性率が十分低いならば、確かに一つずつ検査するよりも、一度混ぜたものを一度検査し、それが陽性ならばもう一度一つずつ再検査するという手法でPCR検査を効率化できるように思います。このような手法はプール方式などと呼ばれているようです。
問題定義
では実際どれくらい効率化できるのかシミュレーションしてみます。現実的には様々な問題があると思いますが、以下では一旦忘れて、極端に理想化した状況で問題を定義します。 N個の検体が得られたとします。以下の操作を行い全ての検体について陽性かどうかをできるだけ少ない検査回数で判断したい、とします。
- N個の検体をM個ずつに分けてそれぞれを混ぜる(プーリング)、これはPCR検査と比べて短時間で行うことができるとする
- プーリングした検体をPCR検査する、ただし検体をどれだけプーリングしても検査1回の所要時間は一定であるとする
- プーリングした検体の検査結果が陰性なら検査終了
- 陽性ならばプーリングに使用したM個の検体全てを一つずつ再検査する
明らかに、全ての検体について一つずつPCR検査すればN回の検査で終了することがわかります。以下ではプーリングによってどれだけ効率化できるのかシミュレーションします。
シミュレーション
サンプルサイズN=100,000、サンプル数1000とし、色々なプーリングサイズMと各検体の陽性率を設定してシミュレーションしました。用いたPythonコードを示しながら結果をみます。 必要なライブラリをimportします
import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib from numpy.random import rand
各種パラメータを設定します。(ここでは陽性率0.01の場合を示しています)
sample_number = 10**5 #サンプルサイズ positive_rate = 0.01 #陽性率 sample_size = 1000 #サンプル数 #プーリングサイズの候補 pool_sizes = [2,3,4,5,8,10,15,20,25,50,75,100,200,500,1000,5000]
サンプルとプーリングサイズに対して合計検査回数を返す関数をここで定義しておきます。
#合計検査数を返す関数 def pcr(pool_size,sample): #pool_size:一度の検査でプールするサンプルの数 #sample:サンプル count=0 count += (len(sample)+pool_size-1)//pool_size#プーリングの検査回数 count += len(np.unique(sample[0:-1:pool_size]))*pool_size#陽性だったプーリングの再検査 return count
これで準備ができたので実際に乱数でデータを生成し、実験します。
#データ生成 samples = [np.insert((rand(sample_number)<positive_rate).cumsum(),0,0) for _ in range(sample_size)] #この後の処理の効率化のためcumsum(累積和)を取っています #シミュレーションを行い結果を保存 rslt = dict() for pool_size in pool_sizes: rslt[pool_size] = [pcr(pool_size,sample) for sample in samples] rslt_binary[positive_rate] = [binary_pcr(sample) for sample in samples]
最後に箱ひげ図で各プーリングサイズでの結果を可視化します。
#箱ひげ図をプロット plt.rcParams["font.size"] = 18 points = tuple(rslt.values()) fig, ax = plt.subplots() bp = ax.boxplot(points) ax.set_xticklabels(tuple(rslt.keys())) plt.title("陽性率"+str(int(100*positive_rate))+"%の場合") plt.xlabel("プーリングサイズ") plt.xticks(rotation=45) plt.ylabel("合計検査回数") plt.axhline(sample_number,color='black',ls='--')
シミュレーション結果
陽性率が1%,5%,10%,30%の場合の結果は以下のようになりました。
 どのグラフも初めプーリングサイズをあげると効率が上がりますが、上げすぎると今度は逆に効率が悪くなっていることがわかります。このようにプーリングサイズは大きすぎても小さすぎてもだめで、陽性率に応じて最適な値が存在しそうです。また各検体の陽性率が小さいほど効率化が期待でき、陽性率が1%の場合100,000件の検体に対して最大で約20000回ほどの検査で十分であることがわかります(約5倍の効率化)。反対に各検体の陽性率が大きいときは、プーリングしてもあまり効率化はできないどころか、一つずつ検査するよりも効率が悪くなることも確かめられました。
どのグラフも初めプーリングサイズをあげると効率が上がりますが、上げすぎると今度は逆に効率が悪くなっていることがわかります。このようにプーリングサイズは大きすぎても小さすぎてもだめで、陽性率に応じて最適な値が存在しそうです。また各検体の陽性率が小さいほど効率化が期待でき、陽性率が1%の場合100,000件の検体に対して最大で約20000回ほどの検査で十分であることがわかります(約5倍の効率化)。反対に各検体の陽性率が大きいときは、プーリングしてもあまり効率化はできないどころか、一つずつ検査するよりも効率が悪くなることも確かめられました。
更に効率的なプーリングサイズ決定アルゴリズム
更に効率よく検査を行う方法はないでしょうか?先程の方法では途中の検査の結果によらずプーリングサイズを固定していましたが、プーリングサイズを検査結果に応じて動的に変化させることでより効率よく検査することが可能そうです(例えば最初は大きなプーリングサイズをとり、その後プーリングサイズを小さくしていく)。ここではプーリングサイズを二分探索的に変化させることで更に効率化を図ります。 具体的なアルゴリズムを述べます。 1.サンプルを前半部分と後半部分のちょうど半分に分けます(奇数個あるときは端数を後半に入れる) 2. 前半部分と後半部分をそれぞれプーリングして検査します 3. 前半、後半それぞれについて 4.陰性ならば検査終了 5.陽性ならば再び前半、後半に分けて2から繰り返す
このアルゴリズムを二分プーリング検査と呼んでおきます。二分プーリングPCR検査では最初にプーリングサイズを固定する必要がなく、その都度の検査結果に応じて、サンプルを半分ずつプーリングして検査することによって動的にプーリング数を変化させながら検査を進めることができます。直感的にこちらの方がプーリングサイズを固定するより効率が良さそうですね。 では実装します。二分プーリング検査は再帰関数を使うと比較的きれいに書けます。
def binary_pcr(sample): N = len(sample) if(N<=1): #サンプルが1個以下ならちゃんと検査する return N if(sample[0] == sample[-1]): #プールしたものが陰性ならそれ以降検査しない return 1 #それ以外の場合左半分と右半分で再び混ぜて検査する return binary_pcr(spcm[:N//2]) + binary_pcr(spcm[N//2:])
二分プーリング検査の結果
二分プーリング検査のシミュレーション結果は以下のようになりました。

プーリングサイズを固定していた先程の方法に比べて、更に良い効率で検査ができていることがわかります。(特に陽性率1%の場合で検体数100,000件に対して合計検査回数が6000回弱ですので16倍ほどの効率アップが見込めます)
検査回数の期待値
検査回数の期待値を出してみようと思います。ここでは簡単のため検体の数は2の冪乗個ある場合を考えます。今検体の数が8個の場合で、プーリングの手順を少し可視化すると次の図のようになることがわかります。
 各水色のブロックがプーリングした検体とみなすことができます。大きいブロックで陽性が出るたびに小さいブロックに分割されてもう一度プーリングされ検査されるイメージです。このブロック単位で何回検査が行われるかの期待値を求めてみましょう。今検体の数を
各水色のブロックがプーリングした検体とみなすことができます。大きいブロックで陽性が出るたびに小さいブロックに分割されてもう一度プーリングされ検査されるイメージです。このブロック単位で何回検査が行われるかの期待値を求めてみましょう。今検体の数を 、陽性率を
とします。検体数が
のブロックに注目するとこのブロックが検査に回されるためには、そのひとつ上の
のブロックが陽性である必要があります。よってそのブロックが陽性になる確率を求めれば良いです。注意としてひとつ上のブロックが陽性になるときそのさらに上のブロックも必ず陽性になるのでそれらを考慮する必要はありません。さて
のブロックが陽性になる確率はプールされた検体のうち少なくとも陽性になる確率なので$(1-(1-p)^{2^{k+1}}$
です。 $2^{k}$ のブロックは合計 $2^{n-k}$ 個あります。よって検査回数の期待値 $EX$ は全ての $k$ についてこれらを足し合わせて
$$ EX=\sum_{k=0}^{n-1}(1-(1-p)^{2^{k+1}})\cdot2^{n-k} $$
となります。また最初に必ず1回を検査するのでこれに$1$を加えた値が全体に期待値となります。
この検査回数の期待値と検体数の比を $n,p$ を色々変えた場合でみてみます。
 陽性率が20%を超えると比が1を超え、プール方式の検査が非効率であることがわかります。次に陽性率が1~10%の場合をみてみると
陽性率が20%を超えると比が1を超え、プール方式の検査が非効率であることがわかります。次に陽性率が1~10%の場合をみてみると
 となり陽性率が2%を下回ると8割以上検査回数が削減されることがわかります。
となり陽性率が2%を下回ると8割以上検査回数が削減されることがわかります。
まとめ
理想的な問題設定のなか、検体をまとめてPCR検査を行うことでコストのかかるPCR検査の回数を減らせることがシミュレーションによって確認できました。ただしプーリングサイズを初めに固定する方法では陽性率によって適切な値を選ぶ必要があります。一方でプーリングした検査の結果に応じて、動的に次の検査のプーリング数を決める二分プール検査ではそのようなことを考える必要がない上、高性能でした。またどちらの手法に関しても陽性率が低いほど効率化の度合いが大きいように見えました。
注意事項
- まず大前提として日本ではプール方式でのPCR検査は行われていないようです
- そもそもPCR検査には偽陽性と偽陰性が一定の確率で出てくるため、プール方式を用いても完璧な検査は行えません
- 現実ではプールした検体が検査をすり抜ける可能性もあるようです
- 際限なく検体をプール出来るという仮定も現実的にはかなり怪しいです
現実問題、プール方式のPCR検査を実施していないのには、専門家や現場の方々にしか分からない理由があるのでしょう。